Case Study / Collective Health
A Shelved Concept Becomes the Foundation for Claims AI
I originated the concept and guided a contract designer through the first version. It was rejected and shelved. Several months later it became the design foundation for Collective Health's claims AI initiative, and I drove it into active development as sole product designer.
The scale of the problem
At a glance
A gap the claims engine could not close on its own
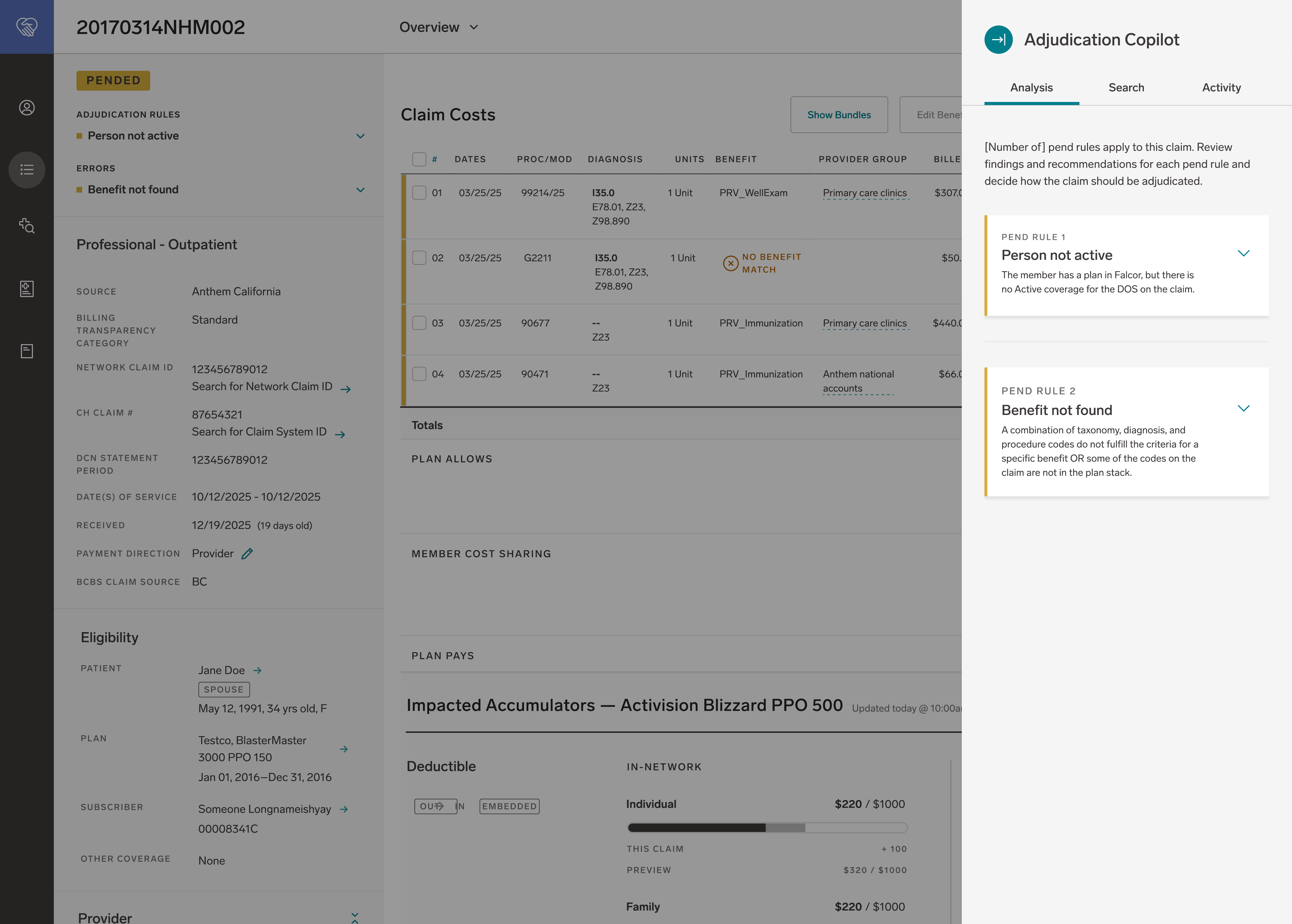
When Collective Health's claims engine cannot process a claim automatically, it pends the claim for manual review by a Member Claims Associate. The company target is 90% auto-adjudication. In 2025 the actual rate was 77 to 80%. That gap represents over 1.3 million claims handled manually every year, and it grows as the member population scales.
The traditional path to closing that gap is engineering new logic into the claims engine directly. Each pend rule requires its own product and engineering effort, competes against other priorities, and can take quarters to ship. With 873 active pend rules and the list updated multiple times per week, the backlog is not shrinking through that approach alone.
Coordination of Benefits claims are the most complex category. They require MCAs to determine which insurance is primary, cross-reference member eligibility across external portals, and follow multi-step decision trees in internal SOPs. MCAs handle 60 per day versus 120 for standard claims.
This project moved through three distinct organizational moments. The design did not change fundamentally. The organizational context around it changed entirely.
First attempt
An AI agent for COB, rejected for the right reasons.
The initial response to slow COB adjudication was to ask what data could be added to the existing screen. I observed the workflow and reached a different diagnosis. MCAs were not slow because they lacked information. They were slow because the process required constantly switching between the claim, an open SOP reference page, and multiple external systems, following a complex decision tree step by step with no system-level support.
I guided a contract designer toward an AI agent that would work through the SOP decision tree and surface structured findings and recommendations. The vision was always broader than COB. Complex claims of all types were the goal. COB was the entry point because it was the most clearly structured and most painful workflow.
The Director of Engineering raised a direct objection: the SOPs were a workaround for a system that could not handle COB automatically. Building an AI to navigate those SOPs faster optimized the workaround rather than fixing the root cause. The concept was shelved. The objection was legitimate. It was also a multi-year engineering commitment with no committed timeline.
Resurfaced
The organization arrived at the same problem statement independently.
A separate initiative formed to address the auto-adjudication gap at the company level. A tiger team proposed a prompt interface: a blank text input where MCAs could ask the AI questions about a claim. It was designed exactly as most AI products look today.
My manager caught wind of the project while I was on leave and recognized what the prompt interface got wrong. She repitched the agent concept with a direct argument: why make users ask questions when the AI already has access to everything it needs? We had the claim data and the SOPs. The agent answered the question before the MCA had to ask it.
The concept was accepted. The formal initiative launched with cross-functional ownership across product, engineering, claims ops, and content design.
Defense
A competing prototype revealed why domain knowledge matters in this space.
Engineering built their own version of the agent in parallel. When I returned from leave and reviewed their prototype, the central problem was immediately visible. The interface presented a prominent DENY recommendation at the claim level. The assumption was that a claim has one outcome: paid or denied.
That assumption does not hold across many claim types. A claim can contain multiple claim lines, each representing a separate service. Denying one line while paying the rest is a normal adjudication outcome, not an edge case. A claim-level DENY recommendation does not represent that accurately and leads MCAs toward the wrong action, with financial and compliance consequences.
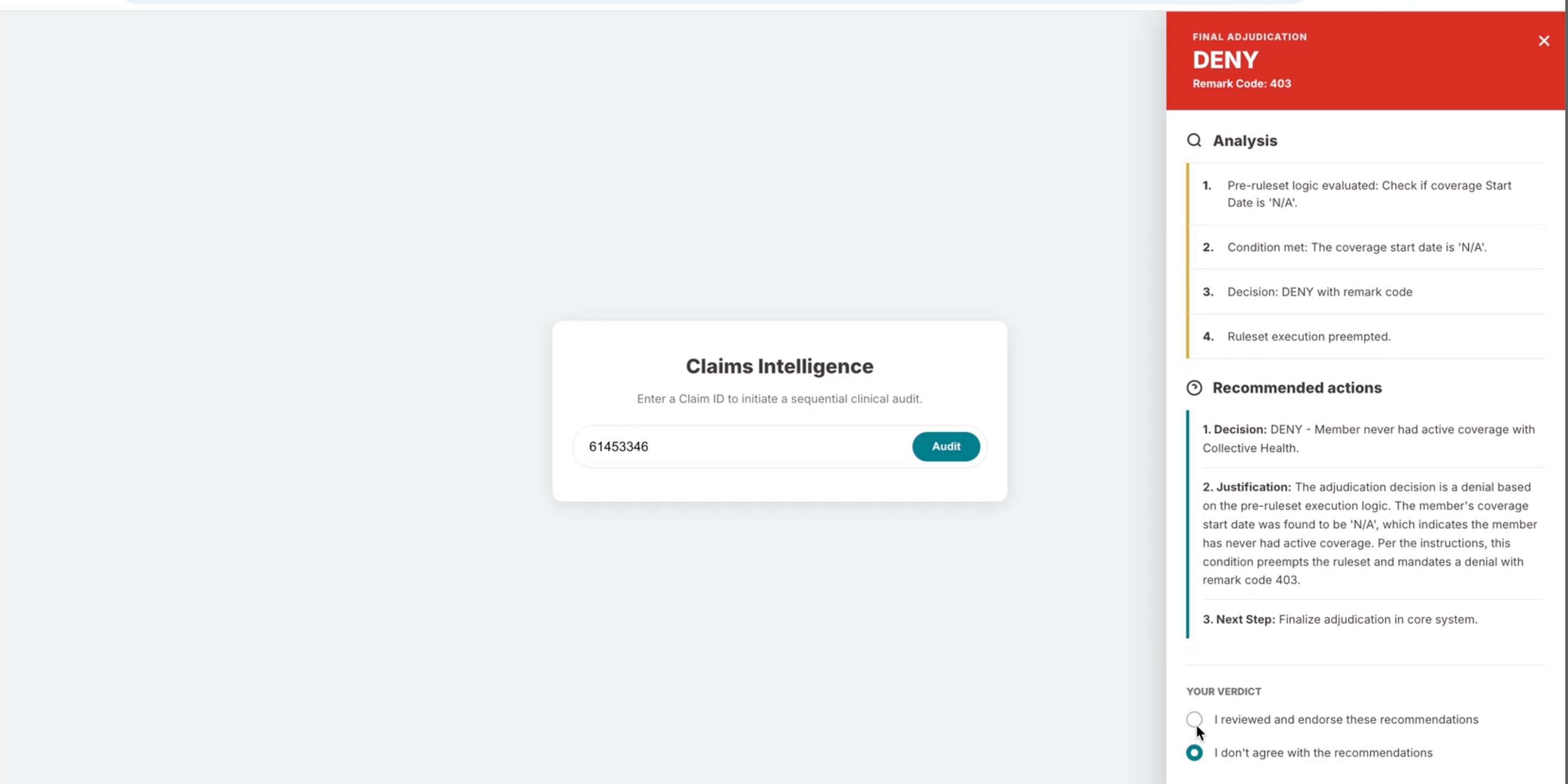
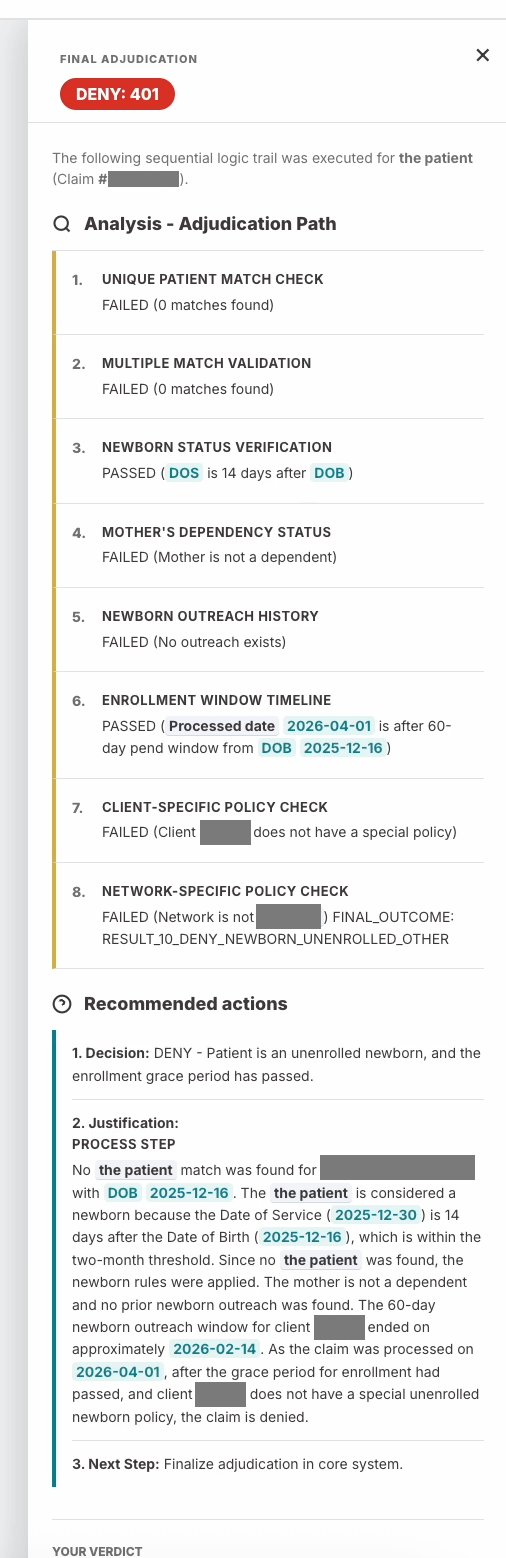
There was a second issue. A previous AI tool at Collective Health had produced inaccurate results and eroded user trust significantly. A design that gave confident recommendations with no visible reasoning would repeat that pattern. Legal scrutiny of AI in health insurance decisions added a compliance dimension: any system recommending claim decisions needed full auditability of how it reached its conclusions.
I documented both issues and defended the agent design in working sessions. The goal was to reframe what the agent needed to do: operate at the claim line level, show its reasoning, and earn trust through transparency.
Current
From chat interface to structured decision support.
The original lo-fi concept had read like a chat. The AI narrated each step in sequence. For a workflow where MCAs move through 60 claims per day, that format was too slow and too verbose. The redesign organized the interface around pend rules instead.
Each pend rule became a decision unit. The AI surfaces a summary of findings with a recommendation per rule. Full reasoning detail is available on demand but not forced. The logic was direct: people use AI for summaries, not narrated walkthroughs. The agent should compress the SOP decision tree into a finding, not recreate it step by step.
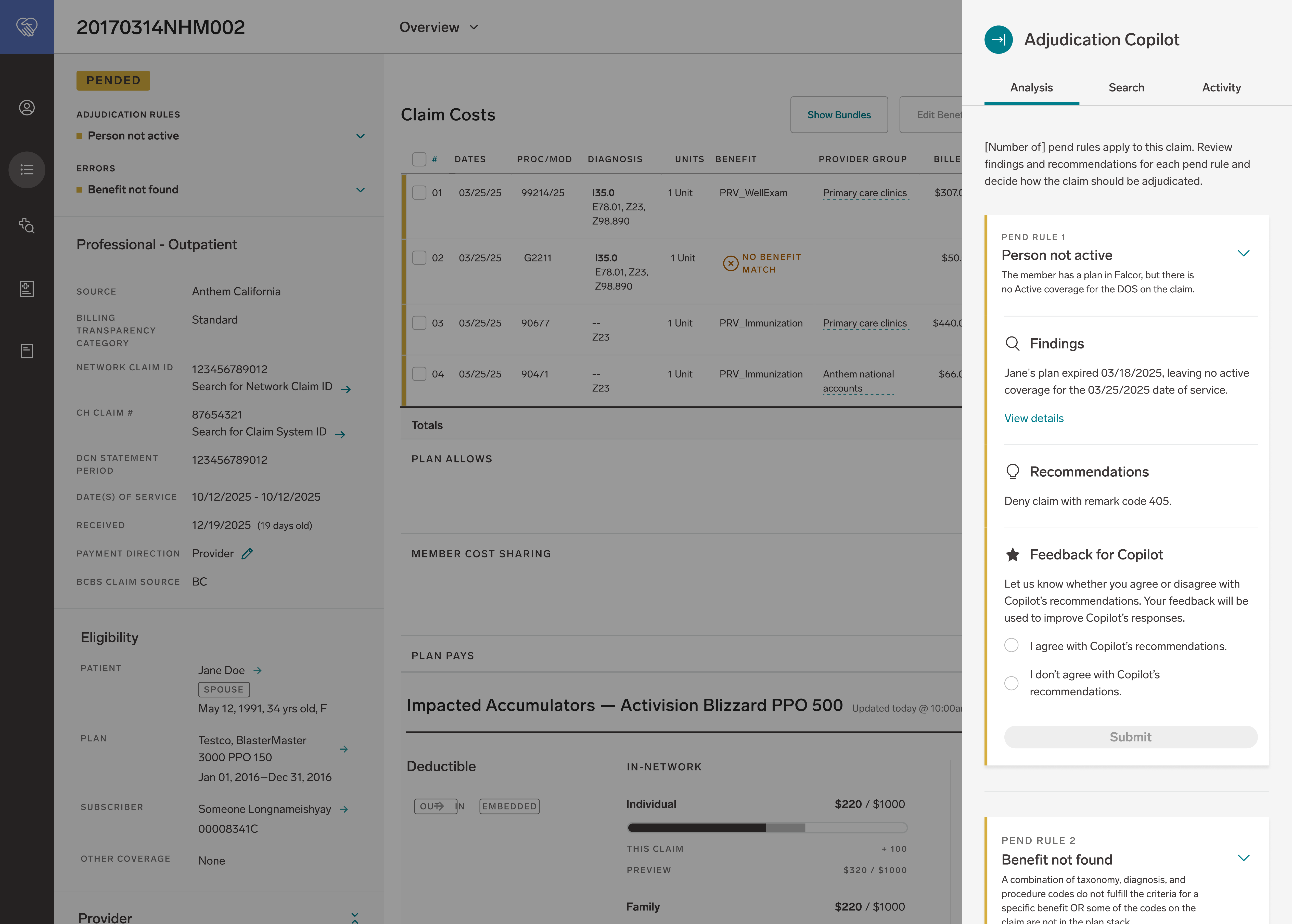
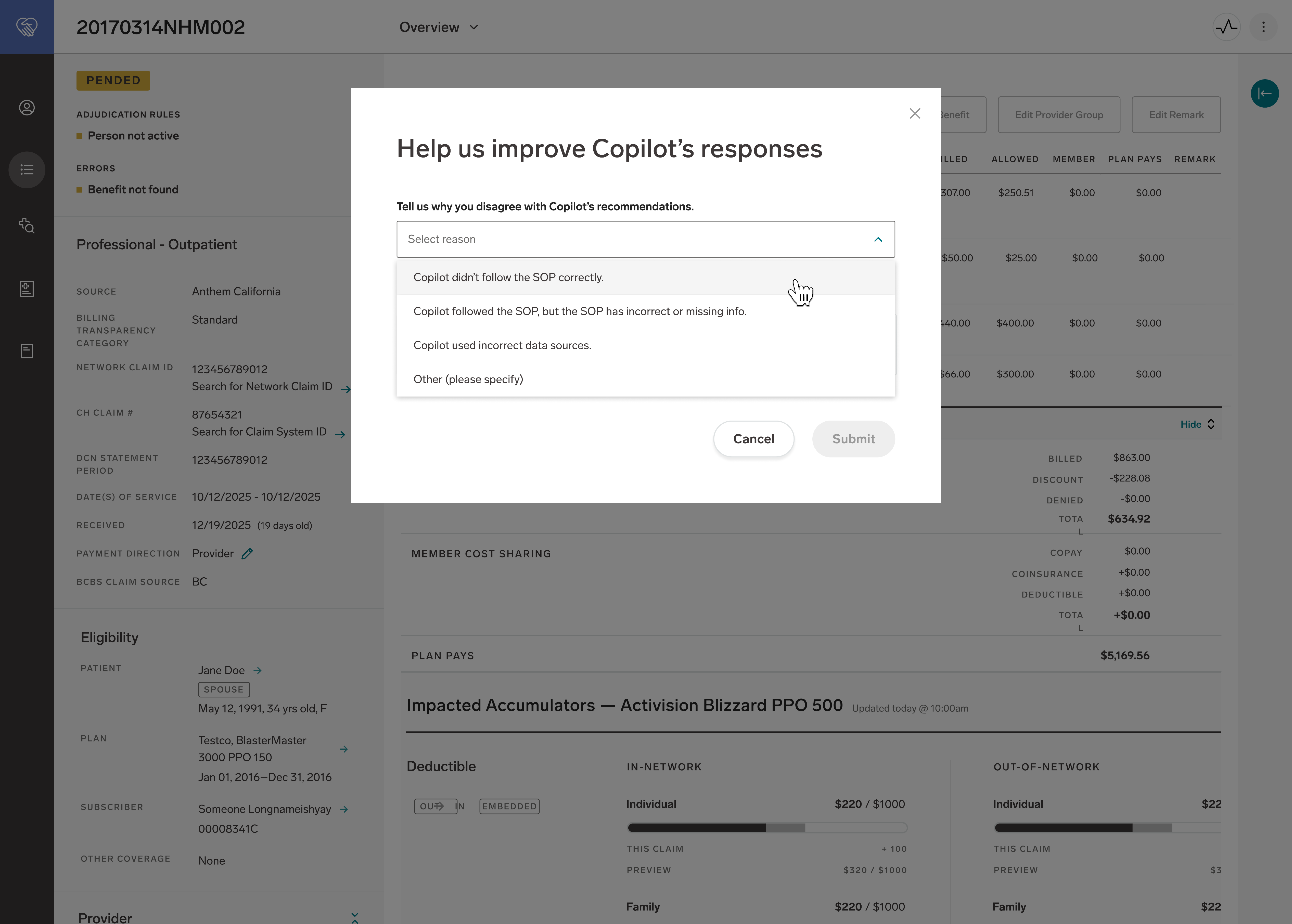
The feedback mechanism required its own design attention. The previous AI tool had made feedback optional. We had seen what that produced: no reliable signal for improvement, no accountability when the model was wrong. This time feedback was required. Working with content design, the challenge was making it feel like completing the task rather than answering a survey. The dropdown captures four specific failure categories, not a binary rating.
Each category points to a different type of problem. A model error, a gap in the SOP, and a bad data source require different fixes. The feedback design was built to make that distinction visible rather than collapsing everything into a single thumbs up or down.
Prompt interface versus AI agent
The difference between these two approaches is not a design preference. It is a claim about what claims adjudication actually requires. Domain knowledge made that difference visible before any user tested either version.
Ask the AI a question. A blank input where MCAs type questions about a claim. Familiar pattern. Puts the burden of knowing what to ask on the user.
Problem: Pended claims adjudication is not an information retrieval problem. MCAs need guidance through a structured decision process, not answers to questions they may not know to ask.
The agent does the reasoning. The agent works through the SOP, identifies relevant pend rules, and surfaces findings with recommendations organized by decision unit.
Result: MCAs review and verify rather than reason from scratch. The design shows its work, which builds trust rather than demanding it.
Optimizing the workaround was the right call
The engineering director's original objection was not wrong. The SOPs exist because the claims engine cannot handle COB automatically. An AI agent that navigates them faster is optimizing the workaround rather than fixing the system.
That tension was named directly in working sessions. A senior claims ops lead saw validity in both positions. The decision to move forward was a deliberate bet: MCAs are doing this work today, and fixing the adjudication logic is a multi-year effort with no committed timeline. Supporting the people doing the work now does not prevent fixing the system later.
100% of AI-adjudicated claims in the pilot will be reviewed by an MCA before any decision is committed. As confidence in model accuracy builds, that percentage decreases.
The pilot is measuring MCA acceptance rate of Copilot recommendations, handle time per pended claim, and the proportion of claims processed with AI assistance versus manually.
What domain knowledge actually buys you
My contribution to this project was not continuous. I guided the initial concept and mentored the contractor who built the first version. My manager resurfaced it while I was on leave. I returned, took over as sole product designer, and have driven it to its current state.
What stayed constant across all three moments was the same core insight. Pended claims adjudication is a structured decision problem, not an information retrieval problem. That insight is what the prompt interface got wrong. It is what the binary claim-level recommendation got wrong. It is what the pend rule structure gets right.
Domain knowledge does not replace design skill. But in a space this complex, it is what lets you recognize the wrong answer before anyone has tested it. That is what happened in the working sessions where the design had to be defended, and it is why the agent design is what engineering is now building.